

Optimizing Redis for Portfolio Analytics at SEI Novus
.png)
"It will be so fast, we won't have to worry about it!"
Ah, if only that were always true. Over the years, I've seen many an engineer tout a hot new technology as panacea for their architecture challenges. Redis isn't exactly hot or new (Dan McKinley even called it "boring"), but sometimes its reputation belies the need for careful configuration and usage.
At SEI Novus℠, Redis is a key component of Alpha Platform, our portfolio analytics engine. However, as our workload grew over the years, keeping Redis stable and performing consistently well posed some challenges. During peak usage, our Redis experienced pauses due to high CPU and memory usage - and unplanned instance restarts. To resolve these issues, we had to leverage its features and apply specific techniques to deliver the best possible experience to our users.
While none of the approaches we applied were particularly novel, we thought that aggregating them into a single article—with some notes on our experience—might be useful for the community.
A quick overview of our approaches:
- Use key expiration and eviction policies
- Purge stale data with lazyfree
- Use Pipelining
- Normalize data using Hash dictionaries
- Avoid HGETALL
- "Get or Put if Absent" with Lua Scripting
The result was Redis CPU and memory that went from this - regularly plateauing at 100% and restarting several times a day:
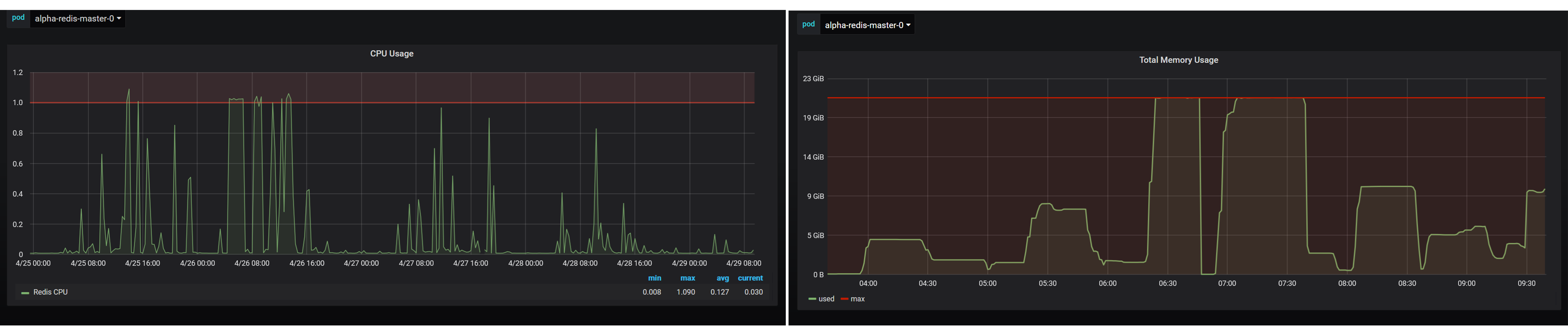
To a much healthier memory and CPU metrics pattern:
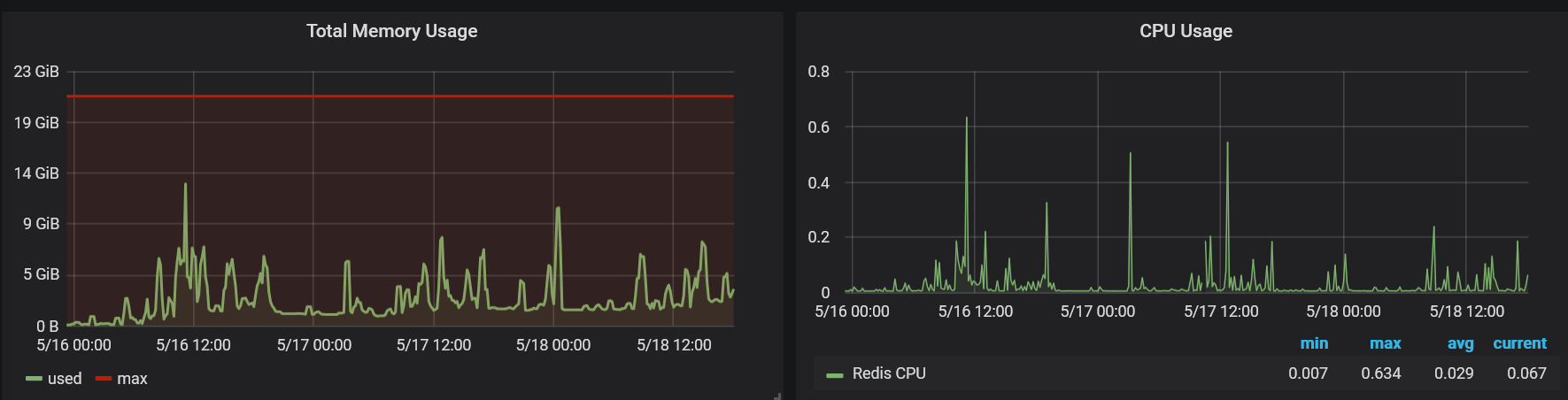
For more details, read on!
Alpha Platform Overview and Redis Use-Case
Before digging into how we improved our Redis stability and performance, it's important to understand the SEI Novus use case and high-level architecture.
Alpha Platform is a portfolio analytics engine implemented in Scala, deployed to a distributed cloud-native infrastructure - with Redis at its core. A typical user might ask: "what were my top-five highest contributing security investments in each market sector over the past 15 years?" Alpha breaks down that request into thousands of work units and spins them out to our distributed compute cluster. The workers then resolve the answer via parallel computations through a multi-stage pipeline.
When a worker finishes a task, it saves intermediate results to Redis and pushes a new task down the pipeline. After completing a given stage, the intermediate ("scratch") data from the prior stage is no longer needed. After all the stages are complete, the pipeline saves its final result to Redis for use by the front-end. Essentially, it's a home-grown map-reduce engine, necessarily so because of the highly-specialized portfolio analytics logic we've baked-in.
As you might expect, the final result is very small relative to the overall data set. Many of our optimizations focused on efficiently managing the intermediate data growth and client operations in that compute pipeline.
Key Expiration, Eviction Policies
First, we needed to ensure our intermediate data didn't blow out Redis memory midway through a request. To prevent this, we wrote our application to leverage Redis key expiration (TTL) extensively. Our typical user makes a request and sees the results in 3 - 30 seconds, so it makes sense that all the "scratch" data shouldn't have a lifespan longer than a few minutes. We chose a generous default TTL of 30 minutes for this intermediate data.
Of course, we don't actually want all objects hanging around for 30 minutes. We need Redis to aggressively free memory on its own, when needed. To accomplish this, we enabled Redis object eviction behavior with the following configuration:
volatile-lru removes objects that have an expire set to "true" (i.e. any TTL at all) that were least recently used. Given our "scratch" objects are typically used seconds after creation - and then forgotten - this algorithm suits our needs.
Redis supports many other eviction algorithms, such as LFU or even a purely TTL-based policy. See the documentation for more details: https://redis.io/docs/manual/eviction/
Regular Purging and Lazy Deletion
As mentioned, the majority of our Redis data is "scratch" with a lifespan of minutes or even seconds. However, some data - the final analytics results - has to stick around in Redis a bit longer. Users need to see how their analysis turned out! Of course, keeping these results around indefinitely would be a "leak," so the application purges stale data regularly, such as after loading a portfolio's end-of-day securities holdings.
Early on, we found that these long-running DEL operations caused CPU spikes, impacting user experience. To mitigate this, we configured Redis for "lazy free" deletion:
These settings ensure that when we delete objects, the deletion happens "eventually" at some point in the future i.e. during a lull in user requests, or when an incoming user request requires free memory.
(Aside: once a analytics results are purged, users seeking a purged result will have to re-run the entire analysis. Knowing this, we gave our users the ability to save particularly meaningful results as permanent "snapshots" in S3. You can see some examples of this feature on our Insights page.)
Pipelining
Redis is blazingly fast. So, unsurprisingly, our profiling revealed - as is often the case - that Redis wasn't the bottleneck at all. Instead, network "round trip time" - time spent in thousands of small requests to Redis server - was the culprit. This network serialize-transfer-deserialize time was often 10x or even 100x greater than the actual time spent in Redis.
The Redis solution to this problem: Pipelining.
You can read more about it in the Redis documentation, but, in short, pipelining allows you "fire hose" a batch of commands to Redis - maxing out the commands packed into each TCP packet - and then receiving the results back from Redis as a single, contiguous response. This can provide a huge performance boost when your applications generates many thousands of small write operations, as does ours.
Pipelining is not without its caveats, however.
As Redis is single-threaded, your pipelined commands will starve out other clients until complete. Instead of pipelining 100,000 LPUSH operations in a single transaction, you should send smaller batches of pipelined commands. This gives your application the efficiency of pipelining, while allowing breathing room for other Redis clients in your application. We applied some judicious heuristics and went with 500 commands per batch - but made it configurable in case we needed to adjust that size at runtime.
Another warning: because of how Redis handles pipelining, your pipelined commands might actually cause OOM (Out Of Memory). When processing a pipeline, Redis does not "stream" results back to you. Rather, it queues up all the results from your commands in a buffer and finally sends them in one result. If Redis does not have enough memory to hold all the results from your commands, the dreaded OOM can occur and your operation will fail.
Lastly, pipelining is a slightly different programmatic model that may require changing your application code (as it did with ours). Inside a pipeline, you can't react to command results interactively. This is because a command result won't arrive until after you've sent all the other commands in your pipeline batch! This makes pipelines best suited to "bulk insert" type operations where you just need to LPUSH 100k objects as fast as possible and only check the return codes of the operations after all are complete.
Side-note: thank you to Debasish Ghosh (@debasishg) for updating scala-redis to fully support pipelining!
https://github.com/debasishg/scala-redis
Data Normalization with Hash "Dictionaries"
Even with aggressive key expiration and pipelining, we found that our Redis was still hitting memory usage of 100%, often sustained for minutes. It was time to optimize our data memory profile.
Because we use Scala, we choose to store our objects as binary structures in Redis, serialized using Kryo (via the Twitter Chill library). Kryo is a terrific library - very fast and efficient. Our data model - not so much.
In binary, a typical record looked something like this in the Scala console:
As you can see, there is a lot of string data in this serialized object. Each record represents a row in a data frame, complete with column names and group names (for hierarchical analysis). This translates to thousands upon thousands of objects with redundant string values. While this flexible approach facilitates a distributed, parallel computation engine, it does not use Redis memory all that efficiently.
Clearly, our application could benefit from some old-school data normalization. Since Redis is just a key-value store with no relational features whatsoever, so we had to write some encoding logic of our own.
Before serializing to Redis, we slimmed down our record case classes to plain old Scala Tuples. This change alone reduced the class name in the Redis record from com.novus.analytics.core.database.api.redis.APIRedisRecord to scala.Tuple8. We probably could have come up with an even more efficient binary format using hand-coded structs...but for our purposes this was good enough and required minimal code changes.
To further reduce the memory overhead, we encode shared string values (column and group names) as integers - aka "foreign keys." These keys reference entries in a lookup table - actually just a Redis Hash. While serializing these records, we use HSET and HSETNX to build up these Hash "dictionaries" on-the-fly, and then reference those same dictionaries when deserializing records from Redis into our application.
So, a record like the following:
...has a corresponding Redis Hash "dictionary" that is something like this:
... allowing our record to be serialized to Redis as a much slimmer object:
This technique certainly adds some complexity to our application, but the result was worth it; the average object size was reduced by upwards of 80%. And the cost of reading and writing the Hash dictionaries for each user request is minuscule compared to the original memory and serialization costs of the original object format.
Redis is fast - but that doesn't mean you should be gluttonous!
See:
- Redis Documentation: "Memory Optimization"
Avoiding HGETALL
Reducing our memory footprint was a major step forward, but we had yet another challenge to overcome. Despite memory barely exceeding 20% throughout the day, we were still suffering sustained CPU of 100% during peak usage, punctuated by untimely restarts.
The Redis SLOWLOG command quickly revealed the root cause: the Redis command HGETALL
Because we were now heavily relying on Hashes to encode and decode our result objects, our application was frequently calling HGETALL to grab the entire hash of int-string mappings. While this kept our code simple, it imposed a heavy burden on Redis: HGETALL is extremely CPU intensive:
See Redis Blog: "Redis Running Slowly? Here’s What You Can Do About it"
Fortunately, there is a simple solution: just use HGET. Each of our records typically only had a subset of all possible column or group name values, so just fetching the few fields needed - instead of the entire Hash - with HGET alleviated the CPU burden on our Redis tremendously.
Lua Scripting
After removing the obvious HGETALL calls from our application, we still saw occasional CPU spikes and even Redis instance restarts during peak usage. As it turned out, we had one remaining HGETALL that was particularly challenging to remove: a "get-or-else-put" operation.
When we build our Hash dictionaries, we had to use application logic like the following:
- HGETALL all the fields for a hash.
- Check if the value we want is in the hash.
- If so, use the existing int → value mapping
- If not, add-and-use a new int → value mapping with HSETNX
If you're familiar with Redis and distributed systems, you probably can see the problem here. We don't hold a lock on the Hash (nor do we want to), so between each HGETALL and HSETNX another process might update the Hash with a different field value - a collision. This means that efficiently setting dozens or hundreds of fields would require many round trips to Redis.
Effectively, we need something like a stored procedure. Fortunately, Redis offers that in the form of embedded Lua scripting via the EVAL command. However, that's a topic worthy of its own article, so we'll set it aside for the future.
See:
- Redis Documentation: Scripting with Lua
In case you were wondering: No Sharding or Clustering... Yet
If you've made it this far, you're probably asking: what about sharding and clustering?
We run Redis in a simple, single-node-per-environment configuration. Our thesis has been that if we can make this simple architecture feasible, sharding should be our last resort. Having spent much of the past decade supporting a clustered, sharded RDMS, we knew we didn't want to introduce such complexity to our application - unless absolutely necessary.
Happily, having applied the approaches detailed in this article, Redis performance and stability improved sufficiently that can continue with this simple architecture. Sharding might come up in the future if we want to leverage multiple cores and scale horizontally, but for now a single Redis is doing the job.
As far as clustering: Alpha Platform is an interactive reporting service, and so does not require fault-tolerant resiliency or "five nines" uptime. If needed, we can still restart our Redis or even FLUSHDB with minor impact: a few seconds of errors, and some users might have to re-run an analysis. Since applying the changes described in this article, neither activity is ever needed, and restarts occur only when planned.
Wrapping Up
In this article, we covered a number of configurations, techniques and gotchas for using Redis effectively. Redis is a solid, fast technology - but you still have to use it responsibly and not assume it will do all the "heavy lifting" for you.
But there's still more ground to cover: Lua scripting. Check out part 2 of this series: Intro to Redis Scripting with Lua